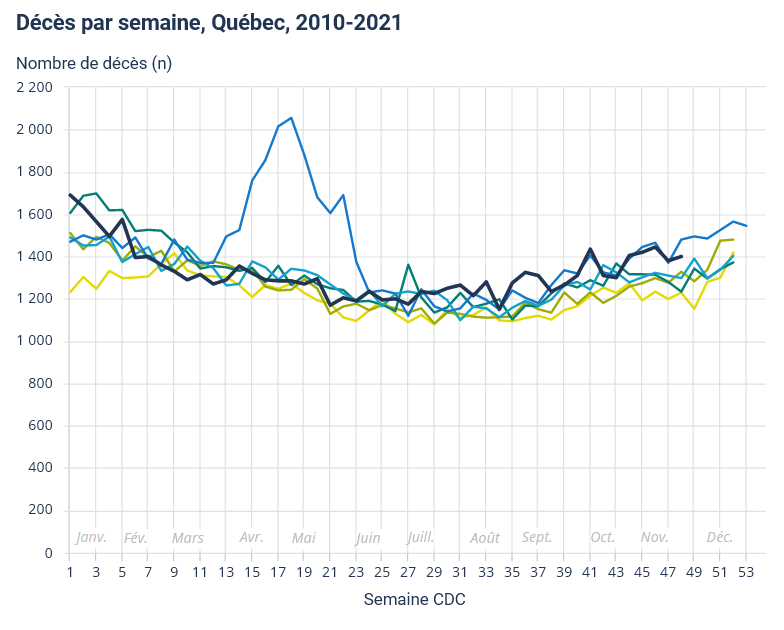
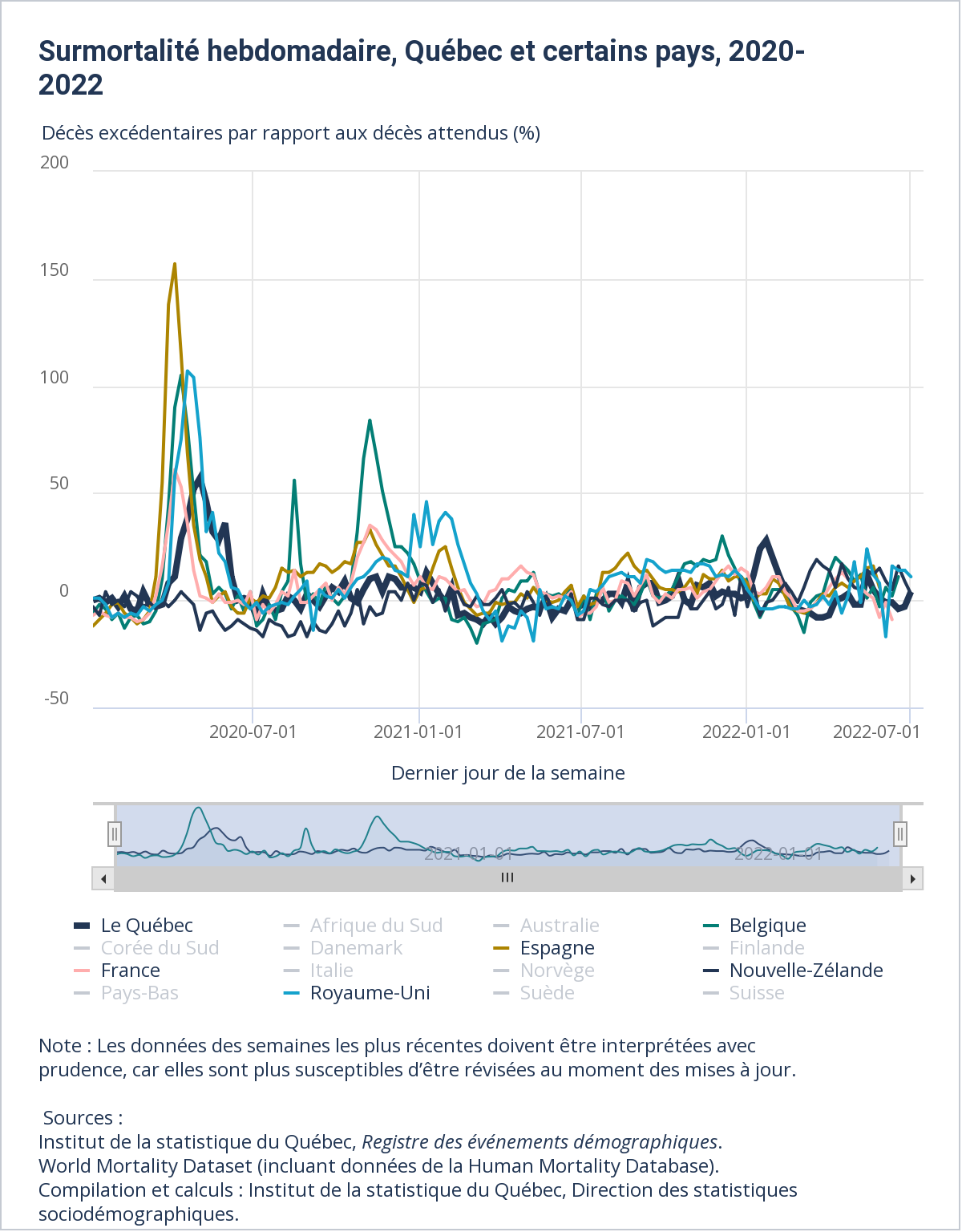
Mise à jour : 2 avril 2026
L’excès de mortalité, ou surmortalité, est défini comme la différence entre une mortalité attendue en l’absence de perturbation, et la mortalité observée. Dans le présent document sont décrits les aspects techniques et les options de paramètres qui ont été développés pour l’estimation de la mortalité attendue à partir des données hebdomadaires de mortalité publiées par l’Institut de la statistique du Québec (ISQ).
Modèles pour l’estimation de la mortalité attendue et ses composantes
Le programme développé à l’aide du logiciel statistique R utilise des modèles de régression inspirés de la méthode proposée par Serfling (1963). Un modèle reposant sur certains principes similaires est également proposé par Verbeeck et coll. (2021). Selon les options choisies, notre modèle permet d’exploiter un modèle linéaire généralisé (GLM, en anglais) ou un modèle additif généralisé (GAM, en anglais) avec une fonction de lien logarithmique. Ces modèles comportent trois composantes : une composante pour prendre en considération la tendance séculaire de mortalité; une composante pour modéliser la saisonnalité et une composante qui tient compte des changements démographiques. Afin de prendre en compte une possible surdispersion des données, une distribution quasi-Poisson est supposée. Les modèles sont ajustés aux données des décès hebdomadaires de façon indépendante pour chaque groupe d’âge, chaque sexe et chaque sous-région.
Approches paramétriques et semi-paramétriques
L’outil développé permet d’estimer la surmortalité de périodes historiques (ex. : saisons grippales ou canicules antérieures) ou de l’année courante (ex. : pandémie de COVID-19). À cette fin, nous proposons des options paramétriques et semi-paramétriques pour la modélisation de la tendance séculaire et de la saisonnalité.
Pour la composante de tendance séculaire, l’option paramétrique utilise des polynômes de degré un à cinq (au choix) modélisés sur une échelle logarithmique, alors que l’option semi-paramétrique utilise des p-splines cubiques.
Pour la composante de la saisonnalité, l’option paramétrique inclut une fonction sinusoïdale de base, qui permet une variation entre une et quatre variations à l’intérieur de chaque cycle, tandis que pour l’option semi-paramétrique, nous utilisons des p-splines cycliques.
Lorsque des options paramétriques sont utilisées, le modèle est ajusté en utilisant une approche GLM et lorsque des composantes semi-paramétriques sont incluses nous utilisons une approche GAM.
Traitement des données aberrantes
Pour définir la mortalité attendue, le modèle permet d’exclure des variations de mortalité exceptionnelles produites par des influences exogènes. C’est notamment le cas de la mortalité par influenza, des vagues de chaleur extrême ou d’autres évènements extraordinaires. Si cette option est retenue, ces observations sont alors considérées comme aberrantes et sont exclues pour la modélisation de la mortalité attendue.
Pour le cas de l’influenza, il est possible pour l’utilisateur de décider la quantité de semaines autour des pics saisonniers d’influenza qui doivent être exclues du modèle. De cette façon, il est possible d’estimer une mortalité attendue « en absence » de la mortalité produite directement ou indirectement par l’influenza, à la manière de l’approche retenue par le consortium de recherche EuroMoMo.
De plus, il est possible d’identifier les données aberrantes de façon automatique. Pour cette fin, l’estimation se fait en deux étapes. Premièrement, on identifie des semaines où la mortalité excède des intervalles de prévision, dont l’utilisateur peut décider le niveau d’incertitude (ex. : 95 %). Deuxièmement, on estime la mortalité attendue en excluant les données aberrantes qui ont été identifiées dans la première étape. De cette façon, on estimera une mortalité attendue « en absence » des phénomènes perturbateurs atypiques.
Définition des périodes de référence et de prévision
Afin d’offrir une flexibilité dans le choix des hypothèses, l’utilisateur peut définir la période de référence qui doit être prise en compte pour la modélisation de la mortalité attendue et la période pour laquelle la mortalité attendue doit être prédite.
Prise en compte de la population à risque
Pour l’estimation des variations hebdomadaires de population par âge et par sexe, nous avons interpolé des estimations de population au 1er juillet entre les années 1971 et 2027. Cette interpolation est faite au moyen de splines naturelles cubiques. À partir de ces estimations, nous calculons l’exposition au risque (en personnes-années) en divisant la population en 52 semaines. Alternativement, l’utilisateur peut choisir de ne pas tenir compte des populations en remplaçant les données de population par des valeurs égales à 1, ce qui revient à modéliser directement les nombres de décès au lieu des taux de mortalité.
Logiciel
Toutes les estimations se font en utilisant le logiciel statistique R. Les modèles GLM se font à partir des fonctions glm() de base, alors que les modèles GAM se font à partir de la fonction gam() du paquet mgcv.
Options retenues pour la surmortalité liée à la pandémie de COVID-19
Fonction servant à la modélisation de la tendance séculaire : tendance log-linéaire (exponentielle) des taux de mortalité
Modélisation de la saisonnalité : option semi-paramétrique des p-splines cycliques
Période de référence pour la définition de la tendance séculaire : 2013-2019 (+ les deux premiers mois de 2020)
Période de projection de la mortalité attendue : 1er janvier 2020 au 31 décembre 2025
Nombre de semaines à exclure avant et après le pic saisonnier : 0
Niveau d’exclusion des données aberrantes (outliers) : 99 %
Niveau d’incertitude des intervalles de projection : 95 %
Procédure de calage des décès attendus selon différentes dimensions
La modélisation est réalisée individuellement pour onze sous-groupes, soit six groupes d’âge (0-49 ans, 50-59 ans, 60-69 ans, 70-79 ans, 80-89 ans, 90 ans et plus), deux sexes et trois regroupements régionaux. Pour déterminer le total (sexes et groupes d’âge réunis), on agrège les décès attendus pour les hommes et les femmes (tous groupes d’âge réunis). Les modélisations distinctes de chaque groupe d’âge et de chaque région sont ajustées proportionnellement sur le total obtenu précédemment pour assurer la cohérence des résultats selon tous les croisements offerts (âge, sexe et région).
Mise à jour du 4 avril 2024
- Le principal élément de la mise à jour est l’intégration des nouveaux chiffres de population par âge et par sexe, diffusés le 21 février 2024 par Statistique Canada. Ceux-ci sont les premiers à être basés sur le Recensement de 2021 (et les phénomènes démographiques observés depuis), ce qui permet une meilleure prise en compte de la population exposée au risque de décéder, lors de la modélisation du nombre de décès attendus. Une nouvelle projection de population est également utilisée pour 2024 et 2025, avec comme point de départ la nouvelle estimation au 1er juillet 2023.
- Comme la forte immigration des dernières années a eu une incidence prononcée sur l’évolution de la population des 0-49 ans, la prise en compte des nouvelles données de population contribue à rehausser légèrement le nombre de décès attendus pour ce groupe d’âge. Autrement dit, la révision à la hausse de la population des 0-49 ans entraîne une révision à la hausse de leurs décès attendus, surtout en 2023, comme l’illustre la figure 1 ci-dessous. Le même effet s’observe aussi sur les décès totaux, mais dans des proportions presque imperceptibles.
- Une méthode de standardisation indirecte a été utilisée pour tenir compte de l’évolution de la structure par âge à l’intérieur des groupes d’âge. Par exemple, chez les 60-69 ans, la mortalité dans les premières années du groupe d’âge (60, 61 ans) est très différente de celle des dernières années (68, 69 ans). La standardisation permet une plus grande comparabilité de la mortalité entre les années, ce qui permet d’éviter les biais occasionnés par l’évolution de la structure par âge interne du groupe d’âge. Ce changement a un effet uniquement sur les estimations par groupe d’âge, notamment chez les 0-49 ans où il contribue à rehausser le nombre de décès attendus, en conjonction avec la prise en compte d’une estimation de population révisée à la hausse (point 2).
- Précédemment, on excluait les données aberrantes au-delà d’un seuil de 95 %. Maintenant, on privilégie un seuil de 99 % pour éviter d’exclure trop de décès lors de la modélisation de la tendance séculaire.
- Précédemment, le nombre total de décès attendus était obtenu en faisant la somme des six modélisations croisant trois grandes régions du Québec et les deux sexes. En raison de la non-disponibilité des nouvelles données démographiques régionales au moment de réviser le modèle, le nombre total est maintenant obtenu en faisant la somme des deux modélisations par sexe, soit les décès attendus pour les hommes et pour les femmes, tous groupes d’âge confondus.
Finalement, il est important de rappeler que l’approche privilégiée pour établir le nombre de décès « normalement attendus » repose toujours sur l’hypothèse d’une poursuite de la tendance prépandémique des taux de mortalité. Cette approche vise à estimer le nombre de décès qu’on aurait pu s’attendre à observer en l’absence de pandémie de COVID-19 afin de mesurer l’effet net de cette pandémie sur la mortalité.
Mise à jour du 3 avril 2025
- Le principal élément de la mise à jour est l’intégration des nouveaux chiffres de population par âge et par sexe diffusés le 25 septembre 2024 par Statistique Canada. Une nouvelle projection de population est également utilisée pour 2025 et 2026, avec comme point de départ la nouvelle estimation au 1er juillet 2024. Ceci permet une meilleure prise en compte de la population exposée au risque de décéder lors de la modélisation du nombre de décès attendus, qui se prolonge maintenant jusqu’en 2025.
- Des notes sont ajoutées pour informer les utilisateurs de l’incertitude grandissante de la projection des décès basée sur la tendance prépandémique, à mesure que l’on augmente l’horizon de projection (maintenant sur six ans, soit 2020 à 2025).
Mise à jour du 2 avril 2026
- Le seul élément de la mise à jour est l’intégration des nouveaux chiffres de population par âge et par sexe diffusés le 24 septembre 2025 par Statistique Canada. Une nouvelle projection de population est également utilisée pour 2026 et 2027, avec comme point de départ la nouvelle estimation au 1er juillet 2025.
Comparaison entre l'ancienne et la nouvelle estimation des décès attendus (mise à jour du 4 avril 2024)

Nombre de décès observés et attendus, par groupe d'âge et sexe, 2020-2023
| Année CDC | ||||||
|---|---|---|---|---|---|---|
| 2020 | 2021 | 2022 | 2023 | 2020-2023 | ||
| Total | Décès observés | 74 378 | 69 964 | 78 175 | 77 301 | 299 818 |
| Décès attendus (nouveaux) | 69 290 | 70 266 | 71 823 | 74 216 | 285 595 | |
| Décès attendus (anciens) | 69 248 | 70 329 | 71 817 | 73 296 | 284 690 | |
| Écart nouveaux/anciens (%) | 0,1 | -0,1 | 0,0 | 1,3 | 0,3 | |
| 0-49 ans | Décès observés | 3 130 | 3 165 | 3 284 | 3 360 | 12 939 |
| Décès attendus (nouveaux) | 2 914 | 2 840 | 2 829 | 2 888 | 11 471 | |
| Décès attendus (anciens) | 2 893 | 2 796 | 2 750 | 2 701 | 11 140 | |
| Écart nouveaux/anciens (%) | 0,7 | 1,6 | 2,9 | 6,9 | 3,0 | |
| 50-59 ans | Décès observés | 4 097 | 3 742 | 3 823 | 3 617 | 15 279 |
| Décès attendus (nouveaux) | 3 999 | 3 806 | 3 651 | 3 544 | 15 000 | |
| Décès attendus (anciens) | 4 003 | 3 831 | 3 690 | 3 541 | 15 065 | |
| Écart nouveaux/anciens (%) | -0,1 | -0,7 | -1,1 | 0,1 | -0,4 | |
| 60-69 ans | Décès observés | 10 181 | 9 922 | 10 649 | 10 365 | 41 117 |
| Décès attendus (nouveaux) | 9 708 | 9 721 | 9 797 | 9 978 | 39 205 | |
| Décès attendus (anciens) | 9 616 | 9 575 | 9 570 | 9 531 | 38 293 | |
| Écart nouveaux/anciens (%) | 1,0 | 1,5 | 2,4 | 4,7 | 2,4 | |
| 70-79 ans | Décès observés | 16 947 | 16 954 | 18 804 | 18 724 | 71 429 |
| Décès attendus (nouveaux) | 16 345 | 16 704 | 17 161 | 17 780 | 67 990 | |
| Décès attendus (anciens) | 16 190 | 16 470 | 16 790 | 17 067 | 66 517 | |
| Écart nouveaux/anciens (%) | 1,0 | 1,4 | 2,2 | 4,2 | 2,2 | |
| 80-89 ans | Décès observés | 23 313 | 21 392 | 24 103 | 23 876 | 92 684 |
| Décès attendus (nouveaux) | 21 546 | 21 830 | 22 302 | 23 199 | 88 877 | |
| Décès attendus (anciens) | 21 694 | 22 170 | 22 884 | 23 806 | 90 554 | |
| Écart nouveaux/anciens (%) | -0,7 | -1,5 | -2,5 | -2,5 | -1,9 | |
| 90 ans et plus | Décès observés | 16 710 | 14 789 | 17 512 | 17 359 | 66 370 |
| Décès attendus (nouveaux) | 14 777 | 15 365 | 16 083 | 16 828 | 63 053 | |
| Décès attendus (anciens) | 14 852 | 15 486 | 16 132 | 16 650 | 63 120 | |
| Écart nouveaux/anciens (%) | -0,5 | -0,8 | -0,3 | 1,1 | -0,1 | |
| Hommes | Décès observés | 36 912 | 35 470 | 39 360 | 38 536 | 150 278 |
| Décès attendus (nouveaux) | 34 426 | 34 922 | 35 737 | 37 058 | 142 142 | |
| Décès attendus (anciens) | 34 422 | 34 977 | 35 749 | 36 508 | 141 656 | |
| Écart nouveaux/anciens (%) | 0,0 | -0,2 | 0,0 | 1,5 | 0,3 | |
| Femmes | Décès observés | 37 466 | 34 494 | 38 815 | 38 765 | 149 540 |
| Décès attendus (nouveaux) | 34 864 | 35 344 | 36 086 | 37 159 | 143 453 | |
| Décès attendus (anciens) | 34 827 | 35 351 | 36 067 | 36 788 | 143 033 | |
| Écart nouveaux/anciens (%) | 0,1 | 0,0 | 0,1 | 1,0 | 0,3 | |
Note
Somme des 52 semaines CDC de chaque année (sans la semaine 53 de 2020 pour permettre la comparaison entre années).
Source
Institut de la statistique du Québec.
Auteurs
Frédéric Fleury-Payeur (démographe émérite [M. Sc.] à l’ISQ), Alexandre Paquette (démographe [M. Sc.] à l’ISQ) et Enrique Acosta (démographe [Ph. D.] et chercheur au Max Planck Institute et au Centre d’Estudis Demogràfics [CED]).
Bibliographie
NEPOMUCENO, Marília R., et autres (2022). “Sensitivity Analysis of Excess Mortality due to the COVID-19 Pandemic”, Population and Development Review, [En ligne], juin, no 48, p. 279-302. doi : 10.1111/padr.12475
SERFLING, Robert E. (1963). “Methods for current statistical analysis of excess pneumonia-influenza deaths”, Public Health Reports, [En ligne], juin, no 78, p. 494–506. [www.ncbi.nlm.nih.gov/pmc/articles/PMC1915276/pdf/pubhealthreporig00078-0040.pdf]
VERBEECK, J., et autres (2021). “A linear mixed model to estimate COVID-19-induced excess mortality”, Biometrics, no 00, p. 1-9. doi : 10.1111/biom.13578